壹沓AI观察:半结构化文本自动抽取关键技术
2020-10-16半结构化文本又称为视觉富文本,与纯文本不同,半结构化文本的语义结构不仅由文本内容决定,更与文本的排版、表格结构、字体的表示方式等视觉元素有关。生活中常见的发票、证件、简历、保险单、采购单据、行业报告以及商务邮件等,均属于半结构化数据。这些文本数据整体离散又局部相关,人工提取信息不仅费时费力,版式的不同更是限制了当下传统算法的可复用性,大大阻碍了企业运行效率的提升。
壹沓科技通过对传统及最新的方法进行探索,同时对几类主流方法的基本思想和目前行业进展进行了分析,提出以领域知识图谱积累与深度学习预训练网络为方向的壹沓认知智能技术重点研发路径,对接公司Cube Robot数字机器人平台,为人工智能技术在多个行业领域落地应用打下扎实的基础。

(半结构化数据样例)
传统手段:基于模板的键值关系识别
在很多实际业务场景中,文档表单的格式基本被限定在有限数量的若干种,通过对样例文档的模板OCR识别,可以用非常小的代价,生成高精度的识别模型。基于模板定义的方法在固定版式和单层次简单键值结构的文档信息抽取中是目前应用最广泛也是最可靠的手段。
然而,随着流程变化越来越频繁、对接关系越来越复杂、数据量呈爆炸式增长,承载数据的版式在很多实际业务中也是难以穷尽,甚至在结构化表单中常常混有连续文本的输入。全自动信息抽取面临重重挑战:最大的困难在于预定义的模板很难全面覆盖实际可能发生的样例,在有限标注成本下抽取更多高质量、高精度的信息成为难题。例如医疗领域经常出现特例数据,往往需要拥有深厚专业知识与实践经验的医疗专家才能读懂,区分,全面人工标注的成本过高,准确识别和抽取数据关系的代价过于昂贵。
热点趋势:深度学习提升信息抽取能力
为了应对当下全自动高质量信息抽取任务的需求,业内提出多种基于深度学习及文本预训练网络的方法。阿里达摩院的StructuralLM、微软的LayoutLM、以及腾讯的结构化文档重建技术,大大推动了相关领域的识别水平。
阿里达摩院NLP团队在BERT的基础上提出优化模型StructBERT,能让机器更好地掌握人类语法,加深对自然语言的理解。在此基础上,又进一步提出融入图像模态知识的预训练语言模型StructVBERT,它能同时理解文本与图像模态的信息,并挖掘二者间的关联以进行有效推理。同样基于StructBERT的模型还有结构化语言模型StructuralLM。它充分利用图片文档数据的二维位置信息,并引入文本框位置预测的预训练任务,帮助模型感知图片不同位置之间词语的关系,这对于理解真实场景中的图片文档十分重要。StructuralLM模型目前在Document VQA榜单上排名第一,同时在表单理解FUNSD数据集和文档图片分类RVL-CDIP数据集上也超过现有的预训练模型。

微软研究院在现有的预训练模型基础上利用文档的多模态信息通过2-D Position Embedding和Image Embedding分别获取半结构化文档的结构和视觉信息,提出了LayoutLM模型。2-D Position Embedding通过光学字符识别(OCR)技术得到文档的结构信息,Image Embedding捕获文档的视觉信息。两者结合使得模型能够有效的捕捉半结构数据中蕴含的语义信息,并在表单理解、票据理解上均取得了不错的成绩。
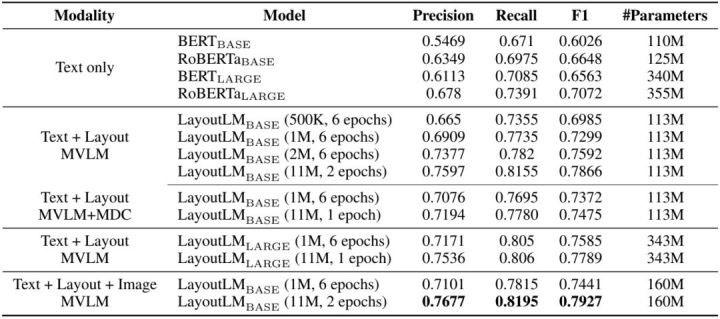
(LayoutLM的表单理解实验结果)
腾讯PCG应用研究小组也在今年6月实现了比传统OCR布局分析更完善的图片转文档的重建技术。通过对拍摄或截屏的图片,通过一系列工作(例如图像增强、实体恢复、语义分割),进行电子文档的重建工作。他们在该项目中使用的是 Bisenet 框架,在学习特征时并行两条支路,一条学习空间细节信息,另一条学习高层语义信息,然后将学到的信息融合,能够更好学习到全局信息和局部信息特征信息。

(腾讯的语义分割)
展望未来:知识图谱打造信息抽取的智能基石
壹沓科技认为,通过深度神经网络对表单内容实现高精度的抽取与识别是近年来人工智能技术在图像和文本两大领域各自实现突破后带来的技术融合大趋势,仅仅依靠神经网络不足以解决面向行业应用高度自动化的流程需求,在实际场景中,依托知识图谱技术增强领域半结构化文档的信息抽取是必经之路。
2020年6月,在NLPCC(CCF国际自然语言处理和中文计算会议) ,搜狗杭州研究院知识图谱组以最高F1值,击败多支国内外顶尖科研机构的参赛队伍,荣获Auto Information Extraction(信息抽取)任务组冠军。团队通过采用Bert+CRF模型,并在模型上加入了标签路径限制 Incomplete Annotations Training(不完全标注训练)、 Self-training(自训练)等多种技术策略,攻克了在未提供大量有标注的人工语料,而只提供不完全的实体词典和大量无标注文本,以及少量有标注集合的情况下抽取高精度模型的行业难题。
壹沓科技在该方向上持续投入,通过知识图谱的积累并结合大规模语料深度学习的预训练模型,在信息抽取等多种任务的场景下取得前所未有的精度进步,并且在品牌方程和数字机器人领域大规模应用。同时壹沓研发团队通过努力显著降低场景应用的启动门槛,在大量少样本、无标注的实际业务推进过程中,真正使得计算机系统拥有专家智慧的成熟智能化系统,并最终实现超越人类水平的自动化文档信息识别和流程处理平台。
关于我们
- 咨询热线 400-821-5161
- 商务合作 BD@1data.info

关注微信公众号
获取更多资讯
壹沓科技(上海)
版权所有 沪公网安备 31010602007083号